Pi lets you switch models mid-conversation. That’s the feature. You start a session on one model, then switch to another with /model or by cycling with Ctrl+P - whichever model fits the next stretch of work best. Most of the time it just works.
Here’s the time it doesn’t.
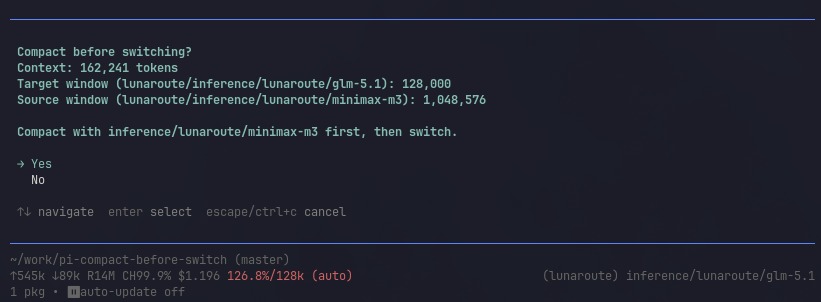
You’re deep in a session on MiniMax M3 and its roughly 1M-token context window. Your conversation has grown to 162,000 tokens - fine, plenty of headroom. Then you switch to GLM-5.1 because it’s the model you want for the next part of the job. You’re thinking about the model, not its context window - and GLM-5.1 tops out at 128,000 tokens. Your conversation no longer fits. Many providers won’t warn you about this; they truncate silently. The model on the other side of the switch is now missing the front of your conversation, and you won’t find out until it starts confidently forgetting things you told it ten minutes ago.
[Read More]